Introduction to GCToolKit
Censum is a GC analysis tool that I hacked together almost 15 years ago. It’s been one of those tools that has been far more useful than I ever could have imagined. For instance, Censum IP ownership was used to help bootstrap JClarity and for quite some time, Censum was instrumental in helping keep the light on. In 2018 the time was finally right and we were finally in a position to open source Censum, something we’d wanted to do for quite some time. Just as we were about to start the process, Microsoft came knocking on the door and we had to put the plan was put on hold. In 2021, the business case I had put together to open source the core of Censum was approved. After the initial exhilaration, it was off to engage in quite a bit of refactoring. Finally, the happy day arrived and the modules named api, parser and vertx were released in Microsoft’s Github repository under the project name GCToolKit.
The journey from Censum to GCToolKit required many decisions. And, it’s far from over which is why, in the next few posts, I want to share experiences, both good and bad, as well as describe ongoing challenges, that hopefully, that still need to be resolved. I’ll start this with a bit of the thinking that went into Censum and has subsequently carried over into GCToolKit.
Integrating Vert.x into Censum
Prior to making use of Vert.x, Censum made use of my home grown (NIH) implementation of a message pump. The idea behind the pump was to push the data from GC logs to end points defined by end users. Refactoring Censum to use Vert.x was surprisingly easy as each of the components in Censum fit nicely into verticles, a core architectural concept within Vert.x. The most difficult aspect was timing the start the message flow and knowing when to shutdown. Dr. Heinz Kabutz contributed StartingGun, a class to manage this.
public class StartingGun {
private static final int UNUSED = 0;
/**
* Synchronization control For StartingGun.
* Uses AQS state to represent count.
*/
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 1L;
protected int tryAcquireShared(int unused) {
return (getState() == 1) ? 1 : -1;
}
protected boolean tryReleaseShared(int unused) {
setState(1);
return true;
}
}
private final Sync sync;
/**
* Constructs a {@code StartingGun}.
*/
public StartingGun() {
this.sync = new Sync();
}
/**
* Wait for the starting gun to fire, without propagating the
* InterruptedException.
*/
public void awaitUninterruptibly() {
sync.acquireShared(UNUSED);
}
/**
* Indicate that the service is ready for operation.
*/
public void ready() {
sync.releaseShared(UNUSED);
}
}
You maybe asking, why does Censum/GCToolKit have a message bus? TLDR; I have a strong bias towards systems that communicate using message sends (aka events) and in this case using events was the obvious play. Thus, Censum was loosely structured according to the diagram below. This allowed us to neatly drop Vert.x into Censum as each of the individual components fit nicely into a Verticle.
The integration was so smooth, it only took a couple of days to complete. Unfortunately, recovering tests was a different story. It took several weeks to refactor existing and add in new tests. I’ll admit, that our test coverage dropped a few percentage points in the process but that said, I don’t think we lost any meaningful tests. That said, improving the GCToolKit test suite is high on my to do list. Finally, my plug for Vert.x is that using it well tend to guide you to a better place. But, I’m getting ahead of the story that I want to start with and that is; how Censum came into being combined with a wee bit of a high level overview of the what and why.
Before Censum
When I first started tuning garbage collectors I relied on a couple of freely available tools. These tools worked but they were limited. The first limitation is that they could only read the most basic logs. For context, the JVM prior to 9 came with more than 60 flags that added information into the log. Unfortunately, each flag has its’ own effect on the log format. For a number of flags, this effect was disruptive. Let’s take a look at a simple case using the exemplar log fragments below.
-XX:+PrintGC
35439.021: ParNew: 6471558K->1974398K(9587008K), 0.0998195 secs] [Times: user=0.58 sys=0.01, real=0.10 secs]
-XX:+PrintGCDetails
35439.020: [GC (Allocation Failure) 35439.021: [ParNew: 4541820K->44475K(5392704K), 0.0989670 secs] 6471558K->1974398K(9587008K), 0.0998195 secs] [Times: user=0.58 sys=0.01, real=0.10 secs]
-XX:+PrintGCDetails -XX:+PrintTenuringDistribution
2017-08-03T16:34:09.668-0500: 35439.020: [GC (Allocation Failure) 2017-08-03T16:34:09.668-0500: 35439.021: [ParNew Desired survivor size 828289840 bytes, new threshold 15 (max 15) - age 1: 28786800 bytes, 28786800 total - age 2: 1540440 bytes, 30327240 total - age 3: 731608 bytes, 31058848 total - age 4: 4397576 bytes, 35456424 total - age 5: 511872 bytes, 35968296 total - age 6: 1925520 bytes, 37893816 total - age 7: 580152 bytes, 38473968 total - age 8: 305768 bytes, 38779736 total - age 9: 383696 bytes, 39163432 total - age 10: 179312 bytes, 39342744 total - age 11: 445272 bytes, 39788016 total - age 12: 341232 bytes, 40129248 total - age 13: 170208 bytes, 40299456 total - age 14: 236024 bytes, 40535480 total - age 15: 10968 bytes, 40546448 total : 4541820K->44475K(5392704K), 0.0989670 secs] 6471558K->1974398K(9587008K), 0.0998195 secs] [Times: user=0.58 sys=0.01, real=0.10 secs]
To be fair, only about 20 of the 60 flags are disruptive but imagine this is only 3 flags and there are 17 others that disrupt the format differently when used in different combinations. Additionally, when GC went concurrent, it was very likely that more than 1 thread would be writing to the GC log at the same time which would corrupt the log file. Surprisingly this corruption, though troublesome, was not as big an issue keeping up with an ever changing log formats. Let me explain.
Prior to JDK 9, GC developers freely changed the format of the logs on a regular basis. It seemed that every time I had the time to work on an interesting new feature, I was instead a adjusting the parsers to accommodate these changes. To further complicate matters, I needed the parsers to work with all versions of logs that maybe thrown over the wall at me which means the current parsers support jdk 1.4.2 through to 17. GCToolKit supports JDK 8-17 but the tests against 1.4.2 logs all still pass so…
Prior to writing Censum I spent quite a bit of time writing scripts that would convert the detailed log formats into a simpler one that the tooling could handle. It soon became clear that tossing away all of this valuable data was a less than a satisfying experience. My first cut at Censum was to focus on data that I was throwing away. The downside is that I was now using two or more tools instead of one. With a little more work, I took Censum to the point where I could (and I laugh as I write this) easily replace the other tools.
My first attempt at parsing was, well, what can one say but, I’m building a parser so the obvious thing to do is use a parser generator and of course that means defining a BNF. So, I threw together a BNF and as can be imagined, it was a disaster and I quickly abandoned this approach. The biggest issue is that the default behavior of a parser is to report and abort paring whenever it encounters an “error”. I wanted something that would deal with the corruption or at worst, ignore it and keep going. Even worse, GC logs often came mixed in with logging from the application. I certainly needed Censum to find the bits I was interested in but ignore the rest unless parts of the rest where things that I should be interested in. With that in mind, I turned to regular expressions. Though this offered a means to weed out the good from the chad, it wasn’t a problem free solution either.
The issue with regular expressions, or at least the ones used in Censum, is that they are all overly greedy which isn’t great for performance. Currently parser performance isn’t great but it’s good enough until you want to scale it up (which we do so challenge #2). That said, there is an issue submitted about improving performance and I (and others) have some ideas that should improve things. Another issue is that named capture groups don’t work the way I needed them to work. Well, it was worse than that as named capture groups in Java didn’t work at the time I was building the initial set of parsers. As nice as it would have been to have used named capture groups, it doesn’t make sense to go back and rework the parsers to make use of them as there are more pressing problems to be looked at. And, the parsers do what the were intended to do, convert GC logs into a sequence of JVMEvent objects.
Events Good!
As I mentioned, I have a strong bias towards event driven systems. This comes from my experiences build large distributed systems, the first was deployed when CORBA was in its infancy and therefore (fortunately) couldn’t make use of it. The systems where we were able to use eventing were simply better by a number of measures. The commonly stated reason for using event driven systems is that it typically has a better scalability and better performance story. It’s not that the performance/scalability story isn’t important, but up there on my list of reasons to use event is that this design often yields better separation of concerns. My views on coupling I’ll save for another post.
Censum
Censum has 4 primary concerns, reading GC logs (data source), converting the logs into a computational friendly format (parser), analyzing the data (aggregators and aggregations) and then presenting the results of the analysis to the user. Of these concerns, GCToolKit takes on the first two while offering a framework to support the third activity.
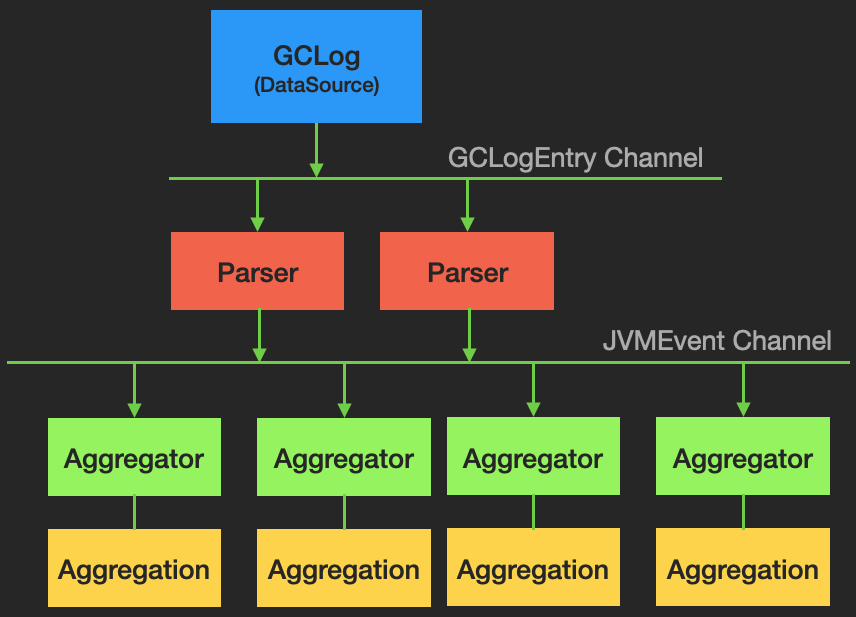
Flow from GCLogEntry to JVMEvent
Another design principal that I’ve found to be very useful and that is to separate things change frequently from those that are stable. In this context, GC logs are historically unstable whereas GC behavior hasn’t changed. Take the format of the log fragment posted above. This more detailed format has more than 6 different forms and this is only includes JDK 5, 6, 6 and JDK 8. Of course, the format in Unified Logging is completely different. It is the role of the parsers to isolate this instability from everything else. It achieves this by producing stable events (JVMEvent). This was the theory, until it was tested by the introduction of Unified Logging (UL).
UL promised that log formats would be stabilized. The cost of this stability was a complete rewrite of logging in the JVM. This change in format as well as the change in the data being logged required a large number of code changes in Censum changes in the data being logged downside was that the underlying data offered by UL changed so much that adapting Censum required more changes than I would have hoped for. For example, a number of new events that were almost identical to existing events needed to be added. It also required the implementation of a whole new set of parsers. Other than that, most of Censum just worked. In cases where a specialization was needed, it was introduced by adding either an abstract super class or an interface and then implementing the specialization in concrete classes. An example of this is the class JavaVirtualMachine. It was converted to an abstract class and the concrete subclasses of UnifiedJavaVirtualMachine and PreUnifiedJavaVirtualMachine contain the specializations. All of the code that was working with JavaVirtualMachine continued to work as it had before.
This Diary isn’t private
A diary class has been a feature in Censum since the beginning. It contains a summary of key features found in the GC log. This includes the version of the log, the type of collectors in use and for pre-unified, flags settings that maybe of interest (One of the work items on the board is to reproduce this feature for UL). Its role is to help Censum setup the workflow shown in the diagram above. Additionally, it can also be queried by the UI to answer questions such as, were all the recommended flags set? The parsers sometimes use the diary to get version information. This helps them correct for known errors in the log files.
Aggregator/Aggregation
Finally I should discuss the idea behind Aggregator and Aggregation. The role of an Aggregator is to collect events of interest off of the JVMEventChannel and extract the data of interest. The Aggregator would then call the Aggregation it was paired with passing in the data to be aggregated. The main idea is that Aggregator knew which events to capture and what data to cull but it didn’t have any idea on how to analyze the data. On the flip side, the Aggregation held the logic to perform the analysis but it doesn’t know anything about JVMEvents. Why? Well, as it turns out, this separation of concerns allows the code to remain DRY. To make this more concrete, here is a simple example. If I want to sum up pause times I can have several Aggregation classes that collect JVMPauseEvent and reuse the same Aggregation to perform the sums.
@Collates(PauseTimeAggregator.class)
public abstract class PauseTimeAggregation extends RuntimeAggregation {
/**
* Record the duration of a pause event. This method is called from PauseTimeAggregator.
* @param duration The duration (in decimal seconds) of a GC pause.
*/
public abstract void recordPauseDuration(double duration);
public abstract void recordRuntime(double runtime);
}
@Aggregates({EventSource.G1GC, EventSource.GENERATIONAL})
public class PauseTimeAggregator extends RuntimeAggregator<PauseTimeAggregation> {
public PauseTimeAggregator(PauseTimeAggregation aggregation) {
super(aggregation);
register(G1RealPause.class, this::process);
register(GenerationalGCPauseEvent.class, this::record);
register(JVMTermination.class, this::record);
}
private void record(GenerationalGCPauseEvent event) {
aggregation().recordPauseDuration(event.getDuration());
}
private void process(G1RealPause event) {
aggregation().recordPauseDuration(event.getDuration());
}
private void record(JVMTermination event) {
aggregation().recordRuntime(event.getEstimatedRuntimeDuration());
}
}
What I wanted to change in Censum was how Aggregators and Aggregations required that the model and view code be modified. This violates Open-Close. Ideally, I wanted to be able to drop in (or reuse) an Aggregation with it’s Aggregator and associated view and just have Censum figure it out. Yeah, I know, not that difficult a feature, it was just every time I thought I’d have time to make this happen, I instead spent my allotted time adjusting the parsers for some new found change in the GC log format. Fixing this was a priority during the effort to extract GCToolKit out of Censum.
Wrapping Up
This explains some of the thought that went into the design of Censum, much of which was brought forward into GCToolKit. Before releasing GCToolKit into the wild, we took the opportunity to payoff some of the technical debt. In the next part of this series I will tell the exciting story of extracting GCToolKit out of Censum. As part of the story, I’ll share with you some of the lessons learned converting the code to make use of Java modules.