Solution to a Puzzling Performance Puzzler
A Puzzling Performance Puzzler
Spoiler Alert
Two points before getting into this. First, my apologies to all those that sent me their solution that I wasn’t able to respond to. Second, I’d encourage you to make your own attempt at this puzzle before reading any further. What follows is my solution so don’t read any further. Spoiler alert, solution about to start. Last warning, now onto my solution.
The Puzzler
On the surface, the puzzle appears quite trivial, take a method (from a larger application), drop it into a test harness and then make it at least 3 times faster. That said, if it really is quite trivial then why do so many developers get tripped up on it? Just to give you a sense of this, every answer I received was lacking in one or more aspects. Some even went so far to replace the supplied test harness with JMH. So why do so many developers get tripped up on this “trivial” puzzler. My honest answer is, I don’t know. But what I do know from my days on a sky patrol was that most accidents happen on the beginner hills and no, it’s not beginner skiers, it’s experienced intermediates to experts. Why? Intermediates to experts forget to apply the fundamentals when on beginner terrain, the forget to keep the downhill ski loaded which causes them to catch an edge and lose their balance. Let’s see how our puzzle causes our programming experts to programatically “catch an edge”.
Establishing a Baseline
The task at hand is to ensure checkInteger runs 3 times faster than it currently does. The means the first step is to sort out how fast is currently runs. To do this I setup a test environment, compiled the code, generated the test data and then ran the test app. My baseline as well as target improvement is as follows.
| Dataset | Correct # | time ms | Requirement (ms) |
|---|---|---|---|
| 1 | 1000000 | 783 | 261 |
| 2 | 500000 | 775 | 258 |
| 3 | 300000 | 959 | 319 |
Now that the benchmark has been established, let’s sort what we need to do to make it run faster. In other words, lets characterize the bottleneck. Normally I would engage in a full on performance diagnostic exercise using my diagnostic process, jPDM. In this case I’ll use prior knowledge for the sake of brevity and throw an execution profile at the problem to see what it can tell us. In these cases, my preference is to use a execution profiler that measures using wall clock time. You can use what you’re comfortable with. I’ve decided to use the sampling profiler found in VisualVM.
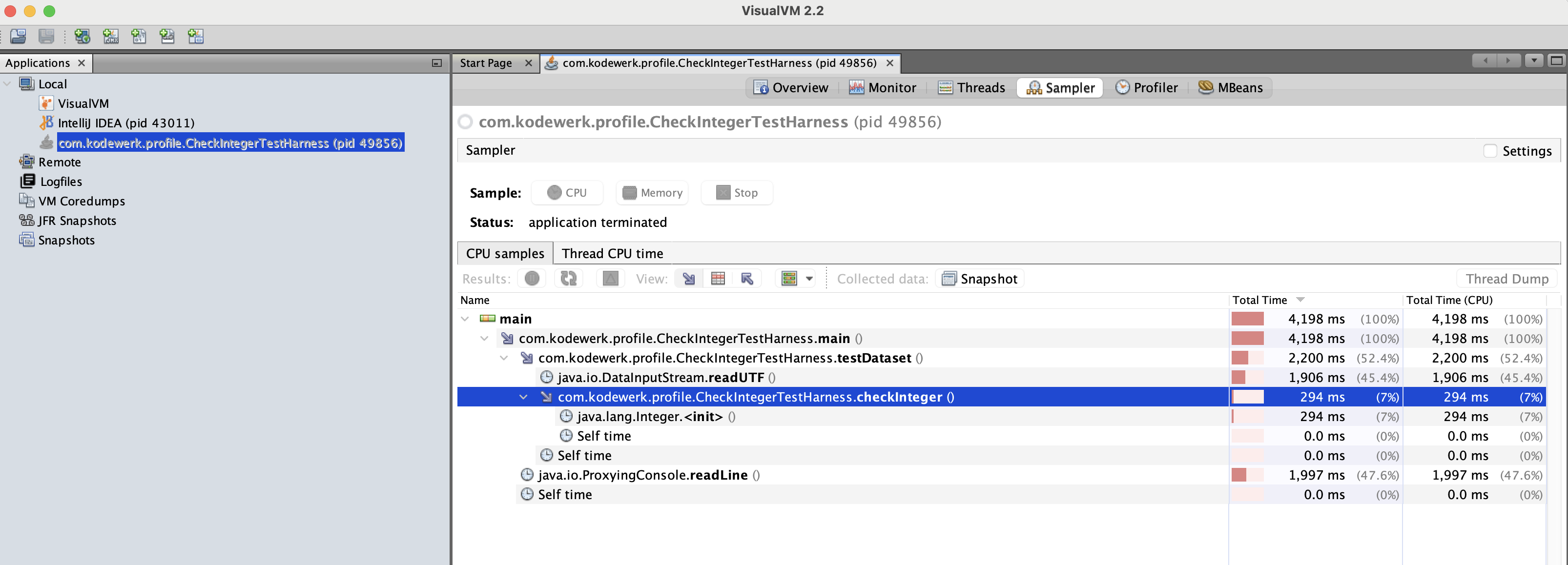
Execution Profile of checkInteger
From this profile we can see that bottleneck is in java.io.DataInputStream.readUTF(). This method, called in the testDataset method, isn’t part of checkInteger. This method is reading in the test data. Before jumping into resolving this bottleneck, let’s step back to get a bigger picture of what all of this means.
Anatomy of the Benchmark
Benchmarks consist of two pieces, the unit under test (UUT) and the test harness. From the perspective CheckIntegerTestHarness, the UUT is the checkInteger method and everything else is test harness. What our profile tests us is that the bottleneck is in the test harness. This violates a fundamental rule of benchmarking. That is, the bottleneck should never be in the test harness. A bottleneck in the test harness will very likely throttle, or otherwise affect, how load is applied to the UUT. The net effect is that problems test harness will invalidate the results produced by the benchmark. Let’s fix the test harness by wrapping the reader with a BufferedInputStream and then re-establish the baseline. If all is well, the baseline should remain the same and the bottleneck should shift into checkInteger. Here is the fix.
DataInputStream rdr = new DataInputStream( new BufferedInputStream( new FileInputStream( dataset)));
The chart below is the new baseline.
| Dataset | Correct # | time ms |
|---|---|---|
| 1 | 1000000 | 52 |
| 2 | 500000 | 57 |
| 3 | 300000 | 171 |
Why did the times change
Wow, these numbers are surprising and they suggest that there is a problem with the timer. This points to another fundamental rule of benchmarking, always check the timers. In many cases timings are used as the measure of success or will guide future decisions. This implies that getting the timers right makes it one of the first things that need to be validated. How can we validate? The answer can vary on a case by case basis but in general, if the UUT is doing nothing, then the timers should reflect that with a measure of 0 (time units go here). In this case let’s replace the UUT with a method that returns true (or false) without performing the calculation. The results are below.
| Dataset | Correct # | time ms |
|---|---|---|
| 1 | 1000000 | 32 |
| 2 | 500000 | 28 |
| 3 | 300000 | 23 |
This test clearly shows that the timer is capturing more than checkInteger. Lets look at how the timer for checkInteger works.
public static void testDataset(String dataset) throws IOException {
DataInputStream rdr = new DataInputStream(new BufferedInputStream(new FileInputStream(dataset)));
long starttime = System.currentTimeMillis();
int truecount = 0;
String s;
try {
while ((s = rdr.readUTF()) != null) {
if (checkInteger(s))
truecount++;
}
} catch (EOFException e) {
}
rdr.close();
System.out.println(truecount + " (count); time " + (System.currentTimeMillis() - starttime));
}
Looking what is between timer start and timer stop, it becomes apparent that the time to read the data from file will be the largest contributor to the non-zero timing. Let’s refactor the test harness to eliminate the file read time from the timing. The solution below (not mine) is one that if offered fairly often.
Catching a Clock Edge
In this run, elapsed time has been ‘fixed’ by having it wrap the call to checkInteger.
public static void testDataset(String dataset) throws IOException {
DataInputStream rdr = new DataInputStream(new BufferedInputStream(new FileInputStream(dataset)));
long accumulatedTime = 0L;
int truecount = 0;
String s;
try {
while ((s = rdr.readUTF()) != null) {
long starttime = System.currentTimeMillis();
if (checkInteger(s))
truecount++;
accumulatedTime += System.currentTimeMillis() - starttime;
}
} catch (EOFException e) {
}
rdr.close();
System.out.println(truecount + " (count); time " + accumulatedTime);
Running the null UUT produces these results.
| Dataset | Correct # | time ms |
|---|---|---|
| 1 | 1000000 | 15 |
| 2 | 500000 | 15 |
| 3 | 300000 | 17 |
Again, wow! These results are surprising as they should be 0ms. In fact even if I replaced the null UUT with the real UUT, the values would be approximately the same and not 0ms as one should expect. Why? The answer is, a millisecond clock has at minimum, a 1ms clock resolution. In other words, it cannot measure any duration less than 1ms. If this is the case, how it is that these numbers are non-zero? The answer is, the counts represent the number of clock edges that have accidentally been captured by the way the timer works. The answer to how does one capture a clock edge is buried in the implementation of currentTimeMillis() and how clocks work in your OS/hardware.
The method currentTimeMillis() make an intrinsic call to C code that returns a struct that contains the current time. This time is rounded to milliseconds. Depending on when the two values have been captured is it possible that this rounding will create an apparent 1ms difference in the times. However this is an artifact of rounding that represents when a clock has changed state, otherwise known as a clock edge. When this happens, the accumulated timer value is catching a clock edge. One could use the nanoSeconds() call instead but that comes with a different set of problems related to how that method is both implemented and supported by the OS and hardware. To solve this problem we should measure all of the calls to checkInteger. To do this we need to solve the test data loading problem.
** Preloading the data **
Let’s eliminate the read time by preloading all of the data into an ArrayList. We can sort out the effects of pulling data from the ArrayList in a future optimization should that prove to be necessary. This code can be found in the listing below. The initial result is in the table table below.
| Dataset | Correct # | time ms |
|---|---|---|
| 1 | 1000000 | 2 |
| 2 | 500000 | 1 |
| 3 | 300000 | 0 |
This is much better but still not perfect as run 1 and 2 show non-zero timings. Maybe adding a warming up phase to the code might help. Let’s run through all 3 datasets twice. The new timings are in the table below.
1000000 (count); time 3
1000000 (count); time 1
1000000 (count); time 1
1000000 (count); time 0
1000000 (count); time 0
1000000 (count); time 0
This produces the desired result so let’s re-establish the baseline by reverting the UUT to the original checkInteger method and confirm that the bottleneck is now in that method. First the baseline followed by the profile.
Here is the new baseline with the target improvements.
| Dataset | Correct # | time ms | Requirement (ms) |
|---|---|---|---|
| 1 | 1000000 | 19 | 7 |
| 2 | 500000 | 20 | 7 |
| 3 | 300000 | 136 | 106 |
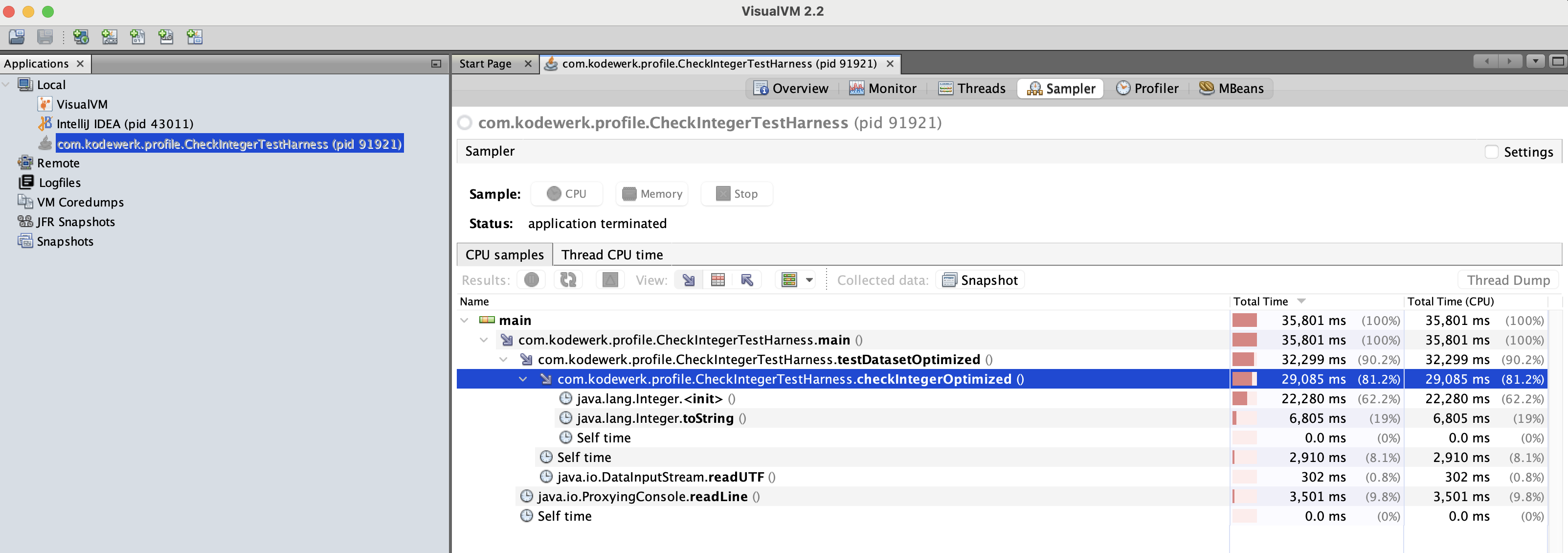
Execution Profile of checkInteger
Refactoring checkInteger
The bottleneck in checkInteger is the conversion of the text representation to an Integer. This reminds me of an old joke. Patient: doctor, it hurts when I do this. Doctor: then don’t do that. Let’s take a look at the requirements to see if we can follow the doctors orders.
The requirements for a valid number are, the first digit is 3, the smallest value is 10 and the largest is 100,000. There are other confusing rules that can be safely ignored. Even the above rules can be reduced to several ranges of valid numbers. They are 30-39, 300-399, 3000-3999, and 30000-39999. The code below is one of a number of ways to satisfy these requirements.
A Contributors Attempt
I ran the optimized code that my friend Chris sent to me using my corrected test harness. The results were 7, 4, and 9ms respectively. While he clearly hit the performance targets, his test harness failed to correct the issue with the timer. My version of the code produced results of 3, 2, 1ms respectively.
Here is the code in it’s final form.
public class CheckIntegerTestHarness {
public static void main(String[] args) throws IOException {
testDataset("dataset1.dat");
testDataset("dataset2.dat");
testDataset("dataset3.dat");
testDataset("dataset1.dat");
testDataset("dataset2.dat");
testDataset("dataset3.dat");
}
public static void testDataset(String dataset) throws IOException {
ArrayList<String> testItems = new ArrayList<>();
DataInputStream rdr = new DataInputStream(new BufferedInputStream(new FileInputStream(dataset)));
int truecount = 0;
String s;
try {
while ((s = rdr.readUTF()) != null)
testItems.add(s);
} catch (EOFException e) {
}
rdr.close();
long starttime = System.currentTimeMillis();
for (String testItem : testItems)
if (checkInteger(testItem))
truecount++;
System.out.println(truecount + " (count); time " + (System.currentTimeMillis() - starttime));
}
public static boolean checkInteger(String testInteger) {
// not checking for null, just throw the exception
if ( testInteger.charAt(0) != '3') return false;
switch(testInteger.length()) {
case 5:
if ( ! Character.isDigit(testInteger.charAt(4))) return false;
case 4:
if ( ! Character.isDigit(testInteger.charAt(3))) return false;
case 3:
if ( ! Character.isDigit(testInteger.charAt(2))) return false;
case 2:
if ( ! Character.isDigit(testInteger.charAt(1))) return false;
break;
default:
return false;
}
return true;
}
}
** Conclusion **
The key to solving this puzzling puzzler is to not lulled into complacency by its simplicity. Without applying rigour it is easy to miss the problems in the test harness. To be fair, it’s not only the simplicity but how the question has been posed that often misdirects people. I’ve been accused of deliberately being misleading. My response to this is, this a miniature version of a real life problem. It is very common for me to be asked to performance tune an application by fixing “this problem” only to recognize that “this problem” isn’t the problem.
As you can see, the purpose of the exercise wasn’t to make the code 3x faster, it was to remind ourselves that benchmarking is a process and this process needs to be followed no matter how big or small the UUT and test harness are. It reminds us that no matter what is asked, it is process that will lead us down the right path to get the desired results. Ignoring this is to risk failure when it matters. As you can imagine, there are more surprising lessons that this tiny piece of code can teach us so we’ll see it again.
I hope you all had fun with the puzzler.